When you create a MySQL Database Service instance in OCI, you have the choice between 3 types:

If you have minutes as RTO (Recovery Time Objective) in case of a failure, you must choose a High Availability instance that will deploy a Group Replication Cluster over 3 Availability Domains or 3 Fault Domains. See Business Continuity in OCI Documentation.
These are the two options:


Natural disasters happen – fires, floods, hurricanes, typhoon, earthquakes, lightning, explosion, volcanos, prolonged shortage of energy supplies or even acts of governments happen which could impede things. Having a DR copy of the data can be important.
And, of course you will need to consider legal aspects as well. Case in point , compliance to GDPR would apply where you define your main data center for your data but also your DR data center as well. My example does DR without consideration of data compliance limitations. Given large number of choices you can select from a solution should exist that satisfies DR and compliance. See – https://www.oracle.com/cloud/data-regions/
The deployed DR instance can also be used for some read/only traffic. This can be useful for analytics or to have a read/only report server in different regions too.
Architecture
Let’s see how we can deploy such architecture:

I won’t cover the creation of the MySQL HA instance as it’s straightforward and it has been already covered.
But please pay attention that by default the binary logs are kept only one hour on a MDS instance:
SQL > select @@binlog_expire_logs_seconds;
+------------------------------+
| @@binlog_expire_logs_seconds |
+------------------------------+
| 3600 |
+------------------------------+
In case you know that this time will be too short, before provisioning your HA instance, you can create a custom configuration where the value of binlog_expire_logs_seconds is higher. But this will also consume more disk space on your instances.
Back to the architecture, we have a different VCN in each region.
To create the new standalone instance that will be used as DR (in Frankfurt), we need:
- verify that we have a DRG (Dynamic Routing Gateway) to peer the different regions
- create a dedicated user for replication on the current HA instance
- dump the data to Object Storage using MySQL Shell
- create the new instance in another region using the Object Storage Bucket as initial data
- create the replication channel
Peering the Regions
Peering in different regions is not trivial, but it’s maybe the most complicated part of this architecture as it requires some extra knowledge that is not focused on MySQL only.
The best is to follow the manual about Peering VCNs in different regions through a DRG.
I will try to summarize it here, too.
We start by creating a Dynamic Routing Gateway in both regions (Ashburn and Frankfurt):

We create them, I called them DGR_gerrmany and DGR_usa. This is how they are represented:

When both DGRs are created, I first attach them to their VCN:


And I do the same for the VCN ins USA.
Now we can go back in the DRG page and create the Remote Peering Connection (RPC):

Then we decide which side will initiate the connection. I decided to establish it from USA, so I need the RPC_to_usa OCID:

And on the other side we use it to establish the connection:


After a little while, the RPC will become Peered:

Finally, we need to create the entry in the Route Tables for both VCNs. We need to add the rule to join the other network in the default and private-subnet routing table like this:

And we need to use the other range in Germany to route to USA (10.0.0.0/16). Don’t forget to add those rules in the private subnet routing table too:

This part is now finished, we can go back to MySQL…
Dedicated Replication User
On the MySQL HA instance, we create the user we will use for the replication channel:
SQL> CREATE USER 'repl_frankfurt'@'10.1.1.%' IDENTIFIED BY 'C0mpl1c4t3d!Passw0rd' REQUIRE SSL; SQL> GRANT REPLICATION SLAVE ON *.* TO 'repl_frankfurt'@'10.1.1.%';
If we plan to have multiple DR sites, I recommend to use a dedicated user per replica. Pay attention to the host part that needs to match the Private Subnet range of the other region.
Dumping the Data
Now we need to dump the data directly into a Object Storage Bucket.
We first create a bucket on OCI’s Dashboard in the destination/target region. In this case Frankfurt:
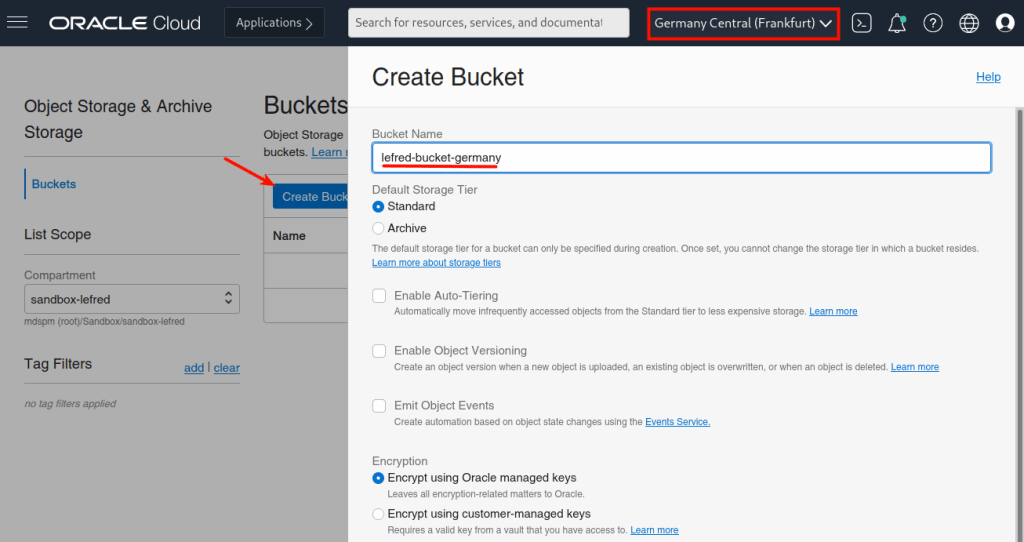
On the compute instance where we have installed MySQL Shell, we also need an oci config file. We can create it from OCI Dashboard for our user (Identity -> User -> User Details):

We need to download the keys if we choose to generate them and copy the content of the config in ~/.oci/config. We need to set the private key’s location and filename:

As I want to dump into an Object Storage Bucket that is located in Germany, I will also have to change the region in ~/.oci/config to point to eu-frankfurt-1.
It’s time to use MySQL Shell, bigger is your data, bigger should be the compute instance used for MySQL Shell, more CPU power means more parallel threads too !

It’s mandatory to use the option ociParManifest to create a dump that can be used as initial data import.
The logical dump will expire (won’t be usable anymore) as soon as the latest+1 GTID event present in the dump will be in a binary log that has been purged from the HA instance.
We can see that the dump wrote in our Object Storage Bucket:

Deploy the DR Instance
No we deploy a new standalone instance in the another region as usual but we specify which data to load directly after provisioning of the instance:



And now, a new MySQL Database Instance will be created…
Connection to the new MySQL Instance
Now we need to verify that the Private Subnets of each VCNs accept connections to MySQL Classic (3306) and X (33060) Protocol. In their Security List for the Private subnet we need to find the following rules:

Let’s try to connect with the Compute instance in USA (Ashburn) to the new instance in Frankfurt using MySQL Shell:

We can verify that the data has been already imported:
SQL > show databases;
+--------------------+
| Database |
+--------------------+
| bikestores |
| dvdrental |
| information_schema |
| mysql |
| performance_schema |
| sbtest |
| sys |
| tickitdb |
+--------------------+
Perfect ! Now we can retrieve some GTID information:
SQL > select @@gtid_executed, @@gtid_purged\G
*************************** 1. row ***************************
@@gtid_executed: 96a2ea9c-9caf-425d-add1-8663411690d1:1-23308
@@gtid_purged: 96a2ea9c-9caf-425d-add1-8663411690d1:1-23308
1 row in set (0.0973 sec)
And we can compare from the data stored in the file @.json in Object Storage:
[...]
"serverVersion": "8.0.26-u1-cloud",
"binlogFile": "binary-log.000963",
"binlogPosition": 6549228,
"gtidExecuted": "96a2ea9c-9caf-425d-add1-8663411690d1:1-23308",
"gtidExecutedInconsistent": false,
"consistent": true,
"compatibilityOptions": [],
"begin": "2021-08-25 18:37:22"
}
This matches, it’s all good, we can now create the Replication Channel.
Replication Channel
On the new MySQL Database Instance, we use Channels underResources:

We then create a new channel:


After adding all the information, if everything is valid, we will see the active channel:
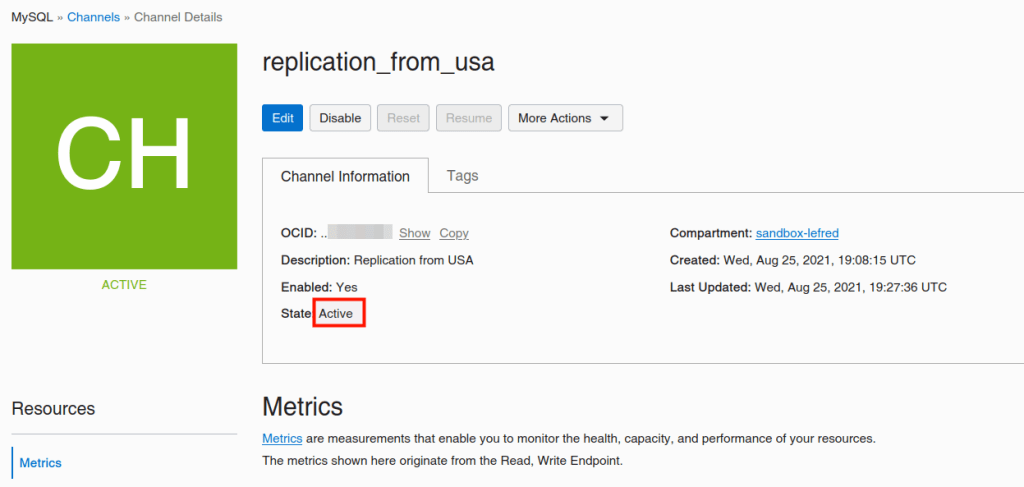
And we can also verify this on the Replica:
SQL > show replica status\G
*************************** 1. row ***************************
Replica_IO_State: Waiting for source to send event
Source_Host: 10.0.1.212
Source_User: repl_frankfurt
Source_Port: 3306
Connect_Retry: 60
Source_Log_File: binary-log.000973
Read_Source_Log_Pos: 826
Relay_Log_File: relay-log-replication_channel.000002
Relay_Log_Pos: 421
Relay_Source_Log_File: binary-log.000973
Replica_IO_Running: Yes
Replica_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Source_Log_Pos: 826
Relay_Log_Space: 644
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Source_SSL_Allowed: Yes
Source_SSL_CA_File:
Source_SSL_CA_Path:
Source_SSL_Cert:
Source_SSL_Cipher:
Source_SSL_Key:
Seconds_Behind_Source: 0
Source_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Source_Server_Id: 1511248356
Source_UUID: 53025e27-0334-11ec-9eec-02001704d2b8
Source_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Replica_SQL_Running_State: Replica has read all relay log; waiting for more updates
Source_Retry_Count: 0
Source_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Source_SSL_Crl:
Source_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 96a2ea9c-9caf-425d-add1-8663411690d1:1-29224
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name: replication_channel
Source_TLS_Version: TLSv1.2,TLSv1.3
Source_public_key_path:
Get_Source_public_key: 1
Network_Namespace: mysql
1 row in set (0.0955 sec)
Conclusion
As you can see many steps are very nicely integrated in MDS, like the replication channel creation, the initial data import at creation time, and more… Of course some networking knowledge (gateway, routing, firewall) is also required to join multiple regions.
And as usual, MySQL Shell does the job too !
Enjoy MySQL and MySQL Database Service !
[…] https://lefred.be/content/setup-disaster-recovery-for-oci-mysql-database-service/ […]
[…] we discovered how to setup Disaster Recovery in OCI MySQL Database Service using inbound/outbound […]
[…] You can find some more information about this process in this article. […]