During the Devopsdays in Hambourg, one of the most recuring discussion was about “packaging vs non-packaging, when and what?”
I won’t try to convince people on what do do when, neither will I say I have the absolute best solution, this post just illustrates the solution I implemented with @zipkid.
Some points aren’t finished yet, not implemented… or we have not yet decided which direction to follow.
First, let’s start we the description of the environment:
A web based application (J2EE) with a MySQL backend, this product is delireved to us as a tgz package.
There are many interconections between gateways, applications, databases, map servers, etc… all these defined in configuration files.
We are using SLES from 10 to 11sp1 and we maintain a bunch of servers: physical machines of different types (dell, IBM blades,..) and virtual machines.
What tools do we use ?
– GNU Linux
– redmine + kanban board plugin to define the tasks
– a pxe installation system (autoyast in sles and cobbler in redhat/centos/fedora) to (re)install the machines
– puppet to deploy the configurations
– git to save all our configurations of puppet
– svn to save other things like specs files (this should be migrated to git)
– puppet-dashboard to have an overview of the deployed machines, an overview of puppet and define some variables we use in our recipes
– rpmbuild to … euh… build the rpms 🙂
– jmeter to perform load test
– nagios to monitor the systems
What is the process then ?
To define the processe, we must first divide it in several categories :
– OS installation and maintenance
– “our business product”
To install a machine, we install a basic image on a machine (virtual or physical) via pxeboot using kind of kickstart files for redhat base system or autoyast for SLES.
We create the node in the dashboard, we add some variables if needed like ip, environment, task. We add the server in the autosign file of puppet.
In the dashboard and puppet we have several different environments that are linked to some git branches. This allow us to test recipes or settings without modifying the production.
Then puppet is started and takes care of everything : vlan interfaces, bonding the interfaces, dns resolving, install the needed package and change the configuration files via puppet.
Nagios checks are also configured by puppet.
For our product, we first create the package (rpm) from the tgz provided by the developers, and put it in our own repository.
After having installed it on the test servers we start some load test scenario.
Back to the big question then: do we package ?
The answer is definetively YES ! To keep a control of what is installed on the system (package version, release and not having orphaned files).
BUT the default configuration files are overidden by the puppet run. conf files, xml, shell scripts, cron jobs are indeed provided by puppet and available in git (which provides us version control too)
Of course puppet runs constantly on every machine to constantly guarantee the desired state, both on production and on the test machines!
This is only dangerous if you don’t test your puppet recepies enough during the development phase.
We don’t start the puppet client in deamon mode but we start the process via cronjobs to avoid any memory usage issues which we encountered with puppetd in daemon mode.
How to improve ?
We would like to improve the load test and automate the build, installation and test on the test server of “our product”.
We plan to use hudson for the CI with jmeter for unit tests and why not tsung for bigger load tests ?
Some open question we still have if we deploy a CI system is how to link a build version with a puppet configuration ? Using a new branch in git linked to a new environment in puppet (and puppetdashboard) doesn’t seem to be an optimal solution. We opted then with a git tag corresponding to the build release and only the last one in testing is deployed on the test machines. If needed we can rollback to a previous tag and package.
It would be also great to automatically test our puppet recipes with a tool like cucumber-puppet.
I think we are going in the right direction, but the road is still long to a fully automated processes with an overview control of all aspects.
But we all agree that puppet already helped us a lot to maintain all our servers.
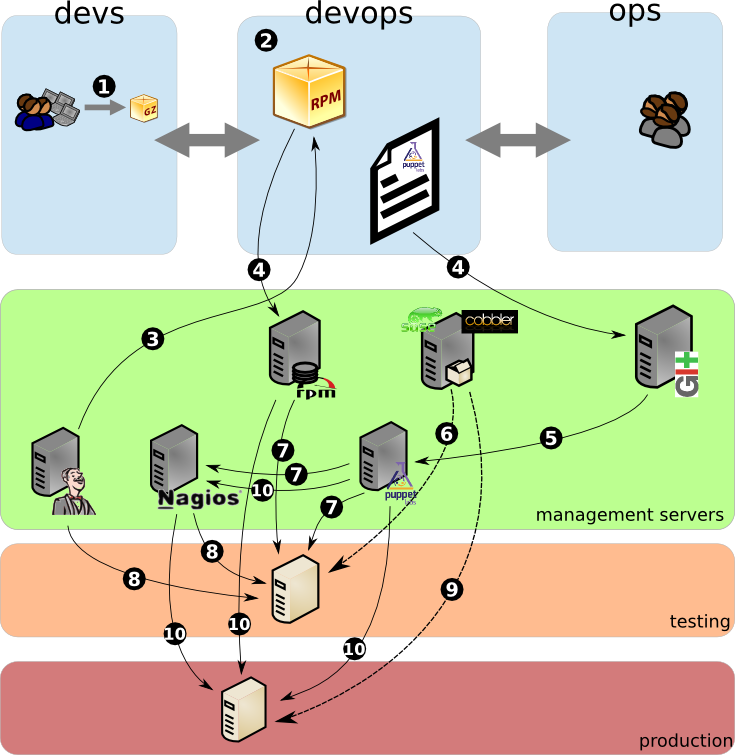
This is a schema illustrating the process :

1. developers provides a tgz with their application (a java compiled application, they also use Hudson to test their package)
2. the “DEVOPS” machine is started ! Devs and Ops collaborate to write the specs for the rpm package and the puppet recipe (dependencies, configuration settings)
3. test the package build and the puppet recipe (with cucumber-puppet)
4. add the package to the rpm repository and commit the puppet recipe to git (and the rpm spec to svn in our case)
5. puppetmaster gets updated with the new recipes
6. this is only in case of a new machine, the machine is automaticaly installed via pxe
7. puppet client installs the needed packages and configure the system as needed
8. puppet also configures nagios and nagios automaticaly startsmonitoring the machine and the services, hudson also starts unit tests and load tests if needed
9. same as point 6
10. puppet installs the needed packages and configuration to the production machine. it also configures nagios to monitor the machine and its services
After a chat session with @themr0c about this post, I would like to add some comments about what I put in the rpms :
An rpm contains the application AND the default configuration files. Puppet changes the configuration files if needed (.conf, .xml, …). Using this method we can always know to which package a config file belongs and we don’t have orphan files on the system.
But we can change easily a config setting (mistake or a specific one per node) without having to rebuild a package (or even worse a package per nodes). This method is also faster.