We recently saw how the new Invisible Column feature works in MySQL since 8.0.23 and how we can use it as a Primary Key for InnoDB tables when no Primary Key was defined.
As I wrote earlier, a good Primary Key is important for InnoDB (storage, IOPS, secondary indexes, memory…) but there is another important domain where a Primary Key is important in MySQL: replication !
Asynchronous Replication
When using “traditional” replication, if you modify a record (UPDATE and DELETE), the record(s) to modify on the replica are identified using indexes, and of course the Primary Key if any. The hidden global 6-bytes auto generated by InnoDB primary key is never used as never exposed and as it’s global, there is no warranty to have the same on the source and the replica. You shouldn’t consider it at all.
If the algorithm was not able to find a suitable index, or was only able to find an index that was non-unique or contained nulls, a hash table is used to assist in identifying the table records. The algorithm creates a hash table containing the rows in the UPDATE or DELETE operation, with the key as the full before-image of the row. The algorithm then iterates over all the records in the target table, using the selected index if it found one, or else performing a full table scan (see the manual).
So if your application doesn’t support an extra key to be used as a Primary Key, using an hidden column as primary key is a option to speed up the operations by the replication applier.
Here is an example of statement where an additional column as Primary Key would break the application:
SQL create table t1 (name varchar(20), age int);
SQL insert into t1 values ('mysql',25),('kenny', 35),('lefred', 44);
Now let’s add a auto_increment column as Primary Key:
SQL alter table t1 add id int auto_increment primary key first;
And now let’s add a record using the INSERT statement as specified in the application:
SQL insert into t1 values ('python',20);
ERROR: 1136: Column count doesn't match value count at row 1
The best is of course to modify the application to change that INSERT statement, but is it possible?
Also how many application are still using SELECT * and then reference the column like col[2] ?
If this is your case, you have two options:
- parse all queries and use the rewrite query plugin
- use an invisible column
In this particular case, the choice is easy (at least for somebody as lazy as I am 😉 ):
SQL alter table t1 modify id int auto_increment invisible;
SQL insert into t1 values ('python',20);
Query OK, 1 row affected (0.0887 sec)
Easy, isn’t it ?
Group Replication
MySQL InnoDB Cluster uses another type of replication: Group Replication.
One of the requirements to use Group Replication is to have a Primary Key (this is why you can use sql_require_primary_key)
Let’s recreate the table without the Primary Key as on the example above and check if the instance can be used in an InnoDB Cluster:
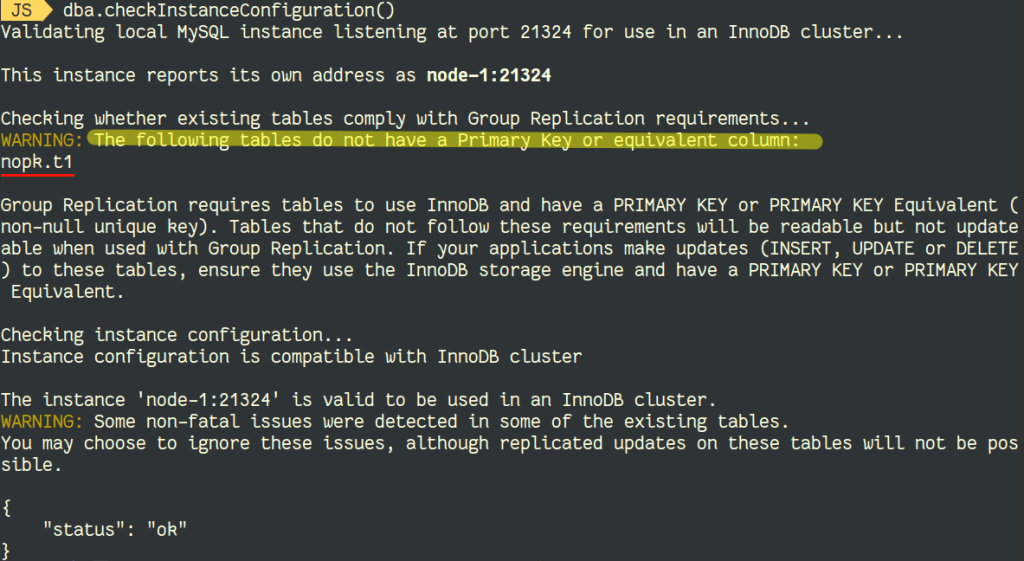
The message is clear, modifications on that table won’t be spread in the cluster.
So let’s add the invisible primary key and check again:


All good !
This means that if you have an application using tables without Primary Key that didn’t allow you to migrate to a full HA solution like MySQL InnoDB Cluster, now thanks to the invisible column, this is possible.
This would help solving Hadoop Hive support for MySQL InnoDB Cluster for example (see HIVE-17306).
[…] Having a Primary Key defined in MySQL InnoDB is mandatory when using Group Replication. In fact it’s always recommended to have a primary key ! (see [1], [2], [3] and [4]) […]